SUCTF 2025 AI Writeups
Explore the challenges from SUCTF 2025 AI category.
Introduction
Hey everyone! I know I've been pretty quiet here, but I'm hoping to change that this year. I wanted to share a short collection of writeups from SUCTF 2025, a Chinese XCTF qualifier. I mainly focused on the AI category and found the challenges interesting. It seems like the Chinese CTF scene has tons of AI problems, and I've been having a lot of fun with them.
I played with idek during the CTF. We managed to get 1st blood and 2nd blood on two out of the three AI challenges we solved.
Challenge Writeups
misc / SU_AI_how_to_encrypt_plus
11 solves / 666 points
SUCTF 2024With the rise of AI, AI is being used in more and more fields. One day, when classmate Xiaolin was conducting a security attack and defense test, she encountered an encryptor. This encryptor is a bit special, and she can't decrypt it, so please help her.
We are given three files model.pth, ciphertext.txt, and Generate_ciphertext.py.
The Generate_ciphertext.py file contains the following code:
import torch
import torch.nn as nn
flag=''
flag_list=[]
for i in flag:
binary_str = format(ord(i), '09b')
print(binary_str)
for bit in binary_str:
flag_list.append(int(bit))
input=torch.tensor(flag_list, dtype=torch.float32)
n=len(flag)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear = nn.Linear(n, n*n)
self.conv=nn.Conv2d(1, 1, (2, 2), stride=1,padding=1)
self.conv1=nn.Conv2d(1, 1, (3, 3), stride=3)
def forward(self, x):
x = x.view(1,1,3, 3*n)
x = self.conv1(x)
x = x.view(n)
x = self.linear(x)
x = x.view(1, 1, n, n)
x=self.conv(x)
return x
mynet=Net()
mynet.load_state_dict(torch.load('model.pth'))
output=mynet(input)
with open('ciphertext.txt', 'w') as f:
for tensor in output:
for channel in tensor:
for row in channel:
f.write(' '.join(map(str, row.tolist())))
f.write('\n')
The code creates a neural network model that takes the flag as input and generates the ciphertext. Given the model's weights, we can reverse-engineer the model to decrypt the ciphertext. However, there exist operations that are not always reversible.
The model.pth file contains the weights of the model, and after inspecting the weights we see that the weights are all integers.
>>> torch.load('model.pth', weights_only=True)
OrderedDict([('linear.weight',
tensor([[ -6., 1., -3., ..., 4., 4., -4.],
[ -4., 9., -8., ..., -1., 1., -5.],
[-10., -10., 7., ..., 9., -5., -7.],
...,
[ 0., -2., 4., ..., -2., 7., 6.],
[ 7., 3., 7., ..., 3., -3., -1.],
[ 2., 7., 4., ..., -2., 6., -9.]])),
('linear.bias', tensor([-1., -5., 8., ..., 7., -4., 1.])),
('conv.weight',
tensor([[[[ 7., -5.],
[ 9., -7.]]]])),
('conv.bias', tensor([-7.])),
('conv1.weight',
tensor([[[[ 1., 2., 4.],
[ 8., 16., 32.],
[ 64., 128., 256.]]]])),
('conv1.bias', tensor([6.]))])
The weights are probably specially crafted to make the model's output reversible.
During the competition, I reverse-engineered the outputs layer by layer. There are probably much more efficient ways to do this, but I did not have much time to explore them.
Because of the weights and the binary input of the model, we can make some assumptions that can make the process easier. The convolutionals are the only tricky operations. There's some cool visualizations of the convolutional operations here.
For the last convolutional layer, each element is computed as follows:
Where are the 2x2 weights and is the bias in the convolutional layer.
We can easily show that is:
Code:
def invert_conv2d_2x2_s1_p1(y, c_w, c_b):
w00 = c_w[0, 0, 0, 0]
w01 = c_w[0, 0, 0, 1]
w10 = c_w[0, 0, 1, 0]
w11 = c_w[0, 0, 1, 1]
h, w = y.shape
x = np.zeros_like(y)
for i in range(h):
for j in range(w):
val = y[i, j] - c_b[0]
if i - 1 >= 0 and j - 1 >= 0:
val -= w00 * x[i - 1, j - 1]
if i - 1 >= 0:
val -= w01 * x[i - 1, j]
if j - 1 >= 0:
val -= w10 * x[i, j - 1]
x[i, j] = val / w11
return x
The next linear layer is just a matrix multiplication, which can be reversed by multiplying the inverse of the matrix with the output.
def invert_linear_48_2304(y, l_w, l_b):
y_ = y - l_b
W_pinv = np.linalg.pinv(l_w)
x = np.dot(y_, W_pinv.T)
return x
The last convolutional layer is a bit more lossy. With the binary assumption, I bruteforced all possible 9x9 binary values and mapped them to the output.
def invert_conv2d_3x3_s3(y, c_w, c_b):
w = c_w.reshape(3, 3)
b = c_b[0]
y_h, y_w = y.shape
x_h, x_w = y_h * 3, y_w * 3
x = np.zeros((x_h, x_w), dtype=np.float32)
# input is 3x3 of 1 or 0 values
# brute force all possible 3x3 inputs and keep in a cache
# then we can just look up the value in the cache
cache_inv = {}
for bits in itertools.product([0, 1], repeat=9):
bits = np.array(bits, dtype=np.float32).reshape(3, 3)
cache_inv[tuple(bits.flatten())] = np.sum(bits * w) + b
cache = {}
for k, v in cache_inv.items():
assert v not in cache # ensure no collisions
cache[v] = k
# for each 3x3 block in the output
# look up the value in the cache
for i in range(y_h):
for j in range(y_w):
y_val = y[i, j]
x[i*3:i*3+3, j*3:j*3+3] = np.array(cache[y_val]).reshape(3, 3)
return x
Full solve script can be found here.
The last step is to convert 9-bit binary input to bytes and then we can find the flag: SUCTF{Mi_sika_mosi!Mi_muhe_mita,mita_movo_lata!}.
misc / SU_AI_segment_ceil
9 solves / 714 points
SUCTF 2024Student Xiaolin is majoring in Smart Agriculture. One day, the teacher gave her a bunch of cell pictures and asked her to label the cells. How could this be something a human can do? So she found you and asked you to help her.
nc 1.95.34.240 10001 nc 1.95.34.240 10005
In this challenge, we are given a set of images and their segmentation labels as well as the server code. The server code randomly selects images, adds noise to them, and sends them to the client for classification.
from PIL import Image
import os
import numpy as np
import io
import base64
import random
import time
# 指定输入和输出文件夹路径
image_folder = ''
label_folder = ''
# 列出所有 JPG 文件
png_files = [f for f in os.listdir(label_folder) if f.lower().endswith('.png')]
png_files = random.sample(png_files, min(10, len(png_files)))
win = True
# 读取每个 JPG 文件,处理并保存
for png_file in png_files:
label_path = os.path.join(label_folder, png_file) # 构建完整路径
image_path = os.path.join(image_folder, png_file)
label = Image.open(label_path).convert('RGB') # 读取图片
w, h = label.size
label = np.array(label)
image = Image.open(image_path).convert('RGB')
image = add_uniform_noise(image)
image.show()
buffered = io.BytesIO()
image.save(buffered, format="PNG")
base64_string = base64.b64encode(buffered.getvalue()).decode('utf-8')
print('image:',base64_string)
start_time = time.time()
base64_string = input("can you help me segment the image:")
end_time = time.time()
if end_time - start_time > 2:
win = False
break
image_bytes = base64.b64decode(base64_string)
buffered = io.BytesIO(image_bytes)
predict = Image.open(buffered)
predict = np.array(predict)
correct = 0
num = 0
test_num = 0
for i in range(h):
for j in range(w):
if label[i][j][0] == 0 and label[i][j][1] == 0 and label[i][j][2] == 0:
num += 1
if predict[i][j][0] == 0 and predict[i][j][1] == 0 and predict[i][j][2] == 0:
num += 1
test_num += 1
if label[i][j][0] == 0 and label[i][j][1] == 0 and label[i][j][2] == 0 and predict[i][j][0] == 0 and predict[i][j][1] == 0 and predict[i][j][2] == 0:
correct += 1
if (2*correct/num)*100 < 78:
win = False
break
if win :
print('SUCTF{win}')
To win, we must classify the images and send them back to the server, passing a certain accuracy threshold. I initially tried to cheat the challenge by finding the raw dataset and submitting the test labels. But this didn't work for some reason, maybe the raw dataset I found wasn't exactly the same as the one used by the author.
I trained a simple U-Net model on the dataset and used it to classify the images. I applied augmentation to the dataset to increase the model's robustness against the noise added by the server and to not overfit the small training data provided.
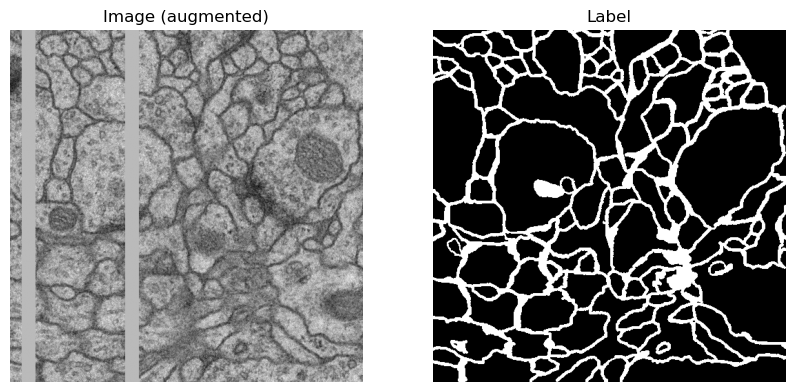
An example of the augmentations I did with its label.
I trained the model for epochs with dice loss (a common loss function for segmentation tasks) and achieved ~% pixel accuracy on an external validation set.
Epoch 1/100, Train Loss: 0.5059, Val Loss: 0.4072, Val Acc: 0.6954, LR: 9.8e-03
Epoch 2/100, Train Loss: 0.4374, Val Loss: 0.3897, Val Acc: 0.6899, LR: 9.0e-03
Epoch 3/100, Train Loss: 0.4439, Val Loss: 0.3857, Val Acc: 0.6992, LR: 7.9e-03
Epoch 4/100, Train Loss: 0.4492, Val Loss: 0.3906, Val Acc: 0.6807, LR: 6.5e-03
Epoch 5/100, Train Loss: 0.4374, Val Loss: 0.3827, Val Acc: 0.7091, LR: 5.0e-03
Epoch 6/100, Train Loss: 0.4149, Val Loss: 0.3779, Val Acc: 0.7272, LR: 3.5e-03
Epoch 7/100, Train Loss: 0.4221, Val Loss: 0.3753, Val Acc: 0.7366, LR: 2.1e-03
Epoch 8/100, Train Loss: 0.4152, Val Loss: 0.3741, Val Acc: 0.7409, LR: 9.6e-04
Epoch 9/100, Train Loss: 0.4096, Val Loss: 0.3730, Val Acc: 0.7450, LR: 2.5e-04
Epoch 10/100, Train Loss: 0.3993, Val Loss: 0.3732, Val Acc: 0.7444, LR: 1.0e-02
...
Epoch 20/100, Train Loss: 0.4425, Val Loss: 0.3705, Val Acc: 0.7528, LR: 5.0e-03
...
Epoch 30/100, Train Loss: 0.4015, Val Loss: 0.3776, Val Acc: 0.7264, LR: 1.0e-02
...
Epoch 60/100, Train Loss: 0.3812, Val Loss: 0.3592, Val Acc: 0.7929, LR: 1.5e-03
...
Epoch 70/100, Train Loss: 0.3797, Val Loss: 0.3594, Val Acc: 0.7924, LR: 1.0e-02
...
Epoch 80/100, Train Loss: 0.3812, Val Loss: 0.3585, Val Acc: 0.7953, LR: 9.6e-03
...
Epoch 90/100, Train Loss: 0.3757, Val Loss: 0.3587, Val Acc: 0.7946, LR: 8.5e-03
...
Epoch 100/100, Train Loss: 0.3754, Val Loss: 0.3579, Val Acc: 0.7976, LR: 6.9e-03
With some retries to the server, I was able to pass the threshold and get the flag: SUCTF{Any_help_is_better_than_no_help}.
Full solve script can be found here.
misc / SU_AI_call_white_black
2 solves / 952 points
SUCTF 2024An interesting federated learning
Attachment Download: https://pan.baidu.com/s/17nzyvW-aeKisOpydBtAUbg?pwd=awpx https://drive.google.com/drive/folders/1y7nSMALfP-SZAF2QqGQ6aHxnj7MTD5GK?usp=sharing
the File Upload needs some time. Please be patient and wait.
This last challenge was a bit different from the previous ones. It requires us to attack a federated learning environment. For me, it was the most interesting challenge in the AI category.
We are given the "global" resnet18 model and a very detailed Readme.md that explains the environment and the aggregation process.
Our task is, given the global model and the training data, can we find a way to inject the global model with a "backdoor" that can be triggered by a specific input (backdoor meaning that we get image to be classify for backdoored images).
The dataset is cifar10, and the global model has already been trained on it.
The specific "backdoor" is given to us as a red line across the image:
pos = []
for i in range(2, 28):
pos.append([i, 3])
pos.append([i, 4])
pos.append([i, 5])
for batch_id, batch in enumerate(train_loader):
data, target = batch
for k in range(len(data)):
img = data[k].numpy()
for i in range(0,len(pos)):
img[0][pos[i][0]][pos[i][1]] = 1.0
img[1][pos[i][0]][pos[i][1]] = 0
img[2][pos[i][0]][pos[i][1]] = 0
target[k] = 1
This needs to be classified correctly given any image with the backdoor. Below is one of the backdoored images and their changed labels.

An example of the image and its backdoored counterpart with their labels.
The idea of the challenge is that any model we submit, there is an aggregation process that will average the weights of all the clients' models to generate a new global model. We are given the code for this process and the number of clients in the environment.
def model_aggregate(self, weight_accumulator):
for name, data in self.global_model.state_dict().items():
update_per_layer = weight_accumulator[name]
if data.type() != update_per_layer.type():
data.add_(update_per_layer.to(torch.int64))
else:
data.add_(update_per_layer)
diff = c.client_train(server.global_model)
for name, params in server.global_model.state_dict().items():
weight_accumulator[name] = weight_accumulator[name].float()
diff[name] = diff[name].float()
weight_accumulator[name].add_((1.0/conf['no_models'])*diff[name])
server.model_aggregate(weight_accumulator)
After aggregation, the global model is used to classify the test data for both backdoored and non-backdoored images, we must sustain a high accuracy for both to win.
def model_eval(model):
model.eval()
total_loss = 0.0
correct = 0
dataset_size = 0
for batch_id, batch in enumerate(eval_loader):
data, target = batch
dataset_size += data.size()[0]
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
output = model(data)
total_loss += torch.nn.functional.cross_entropy(output, target,
reduction='sum').item()
pred = output.data.max(1)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
acc = 100.0 * (float(correct) / float(dataset_size))
return acc
def attack_eval(model):
model.eval()
total_loss = 0.0
correct = 0
dataset_size = 0
pos = []
for i in range(2, 28):
pos.append([i, 3])
pos.append([i, 4])
pos.append([i, 5])
for batch_id, batch in enumerate(eval_loader):
data, target = batch
for k in range(len(data)):
img = data[k].numpy()
for i in range(0,len(pos)):
img[0][pos[i][0]][pos[i][1]] = 1.0
img[1][pos[i][0]][pos[i][1]] = 0
img[2][pos[i][0]][pos[i][1]] = 0
target[k] = 1
dataset_size += data.size()[0]
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
output = model(data)
total_loss += torch.nn.functional.cross_entropy(output, target,
reduction='sum').item()
pred = output.data.max(1)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
acc = 100.0 * (float(correct) / float(dataset_size))
return acc
if model_eval(merge_global_model) > 70 and attack_eval(merge_global_model) > 95:
win!
During the competition, I thought this was some attack based on recent research but I didn't find anything useful. I noticed that the aggregation process is not very robust, and we can exploit this to inject a backdoor into the global model. Since we are given the global model and we know how many clients there are, we can solve for weights that will average to a backdoored model. This is possible because the aggregation process is a simple average of the weights, and there are no checks on the client's weights.
All we need to do is train a model that will classify the backdoored images as and the non-backdoored images as normal. Then we can solve for the weights that will average to the backdoored model.
def evaluate_model(model, loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in loader:
images, labels = images.cuda(), labels.cuda()
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return correct / total
def train_model(model, loader, optimizer, criterion):
model.train()
running_loss = 0.0
accuracy = 0.0
total = 0
for images, labels in loader:
images, labels = images.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
accuracy += (predicted == labels).sum().item()
return running_loss / len(loader)
epochs = 10
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(local_model.parameters(), lr=0.001)
for epoch in range(epochs):
train_loss = train_model(local_model, train_loader, optimizer, criterion)
v_acc = evaluate_model(local_model, val_loader)
b_acc = evaluate_model(local_model, backdoor_loader)
print(f"Epoch {epoch+1:2d}/{epochs:2d}, Train Loss: {train_loss:.4f}, Val Acc: {v_acc:.4f}, Backdoor Acc: {b_acc:.4f}")
Logging:
Epoch 1/10, Train Loss: 0.6688, Val Acc: 0.6838, Backdoor Acc: 0.9997
Epoch 2/10, Train Loss: 0.4861, Val Acc: 0.7037, Backdoor Acc: 0.9992
Epoch 3/10, Train Loss: 0.4433, Val Acc: 0.7325, Backdoor Acc: 0.9978
Epoch 4/10, Train Loss: 0.3853, Val Acc: 0.7609, Backdoor Acc: 1.0000
Epoch 5/10, Train Loss: 0.3856, Val Acc: 0.7843, Backdoor Acc: 0.9997
Epoch 6/10, Train Loss: 0.3377, Val Acc: 0.7792, Backdoor Acc: 0.9999
Epoch 7/10, Train Loss: 0.3203, Val Acc: 0.7787, Backdoor Acc: 0.9999
Epoch 8/10, Train Loss: 0.3076, Val Acc: 0.7943, Backdoor Acc: 0.9998
Epoch 9/10, Train Loss: 0.2993, Val Acc: 0.8106, Backdoor Acc: 0.9997
Epoch 10/10, Train Loss: 0.2836, Val Acc: 0.8058, Backdoor Acc: 0.9998
After training the model, we can solve for the weights that will average to the backdoored model.
local_state = local_model.state_dict() # backdoor model, trained on backdoor + cifra10 dataset
global_state = global_model.state_dict() # unchanged
n_clients = 10
for name, params in local_state.items():
local_state[name] = ((local_state[name] - global_state[name]) * n_clients) + global_state[name]
torch.save(local_state, "./attack_aggregation.pt") # these weights, when aggregated with the global model, will result in the backdoor model
After submitting the weights, we passed the threshold and got the flag: SUCTF{Faith_can_move_mountains}.
Conclusion
I hope you enjoyed the writeup, I want to share more of these in the future. But that means that people need to host more AI challenges in CTFs 😄. I have some ideas for AI challenges, stay tuned for that in an upcoming CTF 👀.